Doctrine Companion to Decision Altitude
There is a quiet lie that shows up in a lot of org charts and LinkedIn profiles.
We act like skills live in adjectives.
- Strategic
- Visionary
- Collaborative
- Influential
These words float near job titles and performance reviews. They are rarely tied to anything you can point at.
If your skill only exists as an adjective, it is not real. It is branding.
Real skills live in artifacts.
- Decision docs
- Specs and architecture notes
- Portfolio dashboards
- Runbooks, SOPs, playbooks (and why you want all three)
- Stakeholder maps and meeting notes
Once you accept that, “skill” stops being a label and starts being a pattern you can see on the page.
From adjectives to artifacts #
Pick any high level adjective you care about.
Strategic.
Where would that show up on paper, at each decision altitude?
- High altitude:
- A portfolio view that connects projects to real objectives and constraints.
- A decision doc that surfaces tradeoffs, not just preferences.
- Mid altitude:
- A program roadmap that shows clear sequencing and dependencies instead of a wish list.
- Risk and opportunity sections that actually affect what gets funded.
- Ground level:
- A sprint plan or workboard that matches the stated priorities, not politics or noise.
- Handoffs that make the next team faster, not slower.
If you cannot show me where “strategic” lives in the artifacts, then we are arguing about a vibe. That is how you end up with panel interviews where the most fluent storyteller wins and the best operator never even gets a callback.
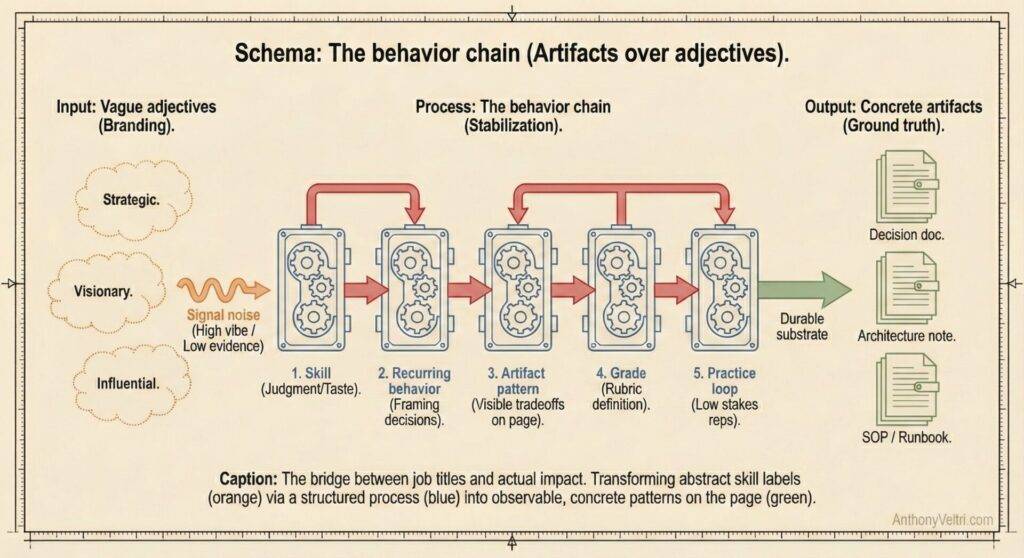
The behavior chain #
This is the core pattern I want to make explicit.
Skill → Recurring behavior → Artifact pattern → Grade → Practice loop
- Skill
- Example: judgment, orchestration, coordination, taste, updating.
- Recurring behavior
- How you frame decisions, structure options, name risks, update plans.
- Artifact pattern
- The way that behavior shows up on the page: clear decision sentence, explicit options, visible tradeoffs, links to metrics and constraints.
- Grade
- A small rubric that answers “what does good look like for this artifact in this environment.”
- Practice loop
- Regular low stakes reps, reviewed against that rubric, with coaching.
- AI can act as a consistent wall to hit against, but humans still own what “good” is.
This is the bridge between your job title and your actual impact. It is also the bridge between “I am strategic, trust me” and “Here is what my thinking looks like in the wild.”
A minimal practice loop for one artifact #
Start extremely small.
- Pick one artifact that matters.
- Decision doc, strategy memo, executive update, incident review, whatever is most leveraged in your role.
- Define what good looks like with someone whose judgment you trust.
- Five to seven bullet points.
- Example for a decision doc:
- Is the decision stated in one clear sentence near the top.
- Are there at least two real options.
- Are stakes and metrics explicit.
- Is there a specific recommendation.
- Are key risks and tradeoffs surfaced.
- Collect three real examples, mark them up.
- Circle what is strong.
- Underline what is muddy.
- Write one sentence about why.
- Turn that into a simple rubric.
- For each bullet, define what a “1” and a “5” look like.
- You can keep this very rough. The goal is direction, not precision.
- Wire in AI as a consistent reviewer.
- Give the model the rubric and the annotated examples.
- Ask it to score new docs, quote the sections it is reacting to, and suggest edits that would move a chosen dimension up by one point.
- Run one low stakes rep each week.
- Take a messy situation or vague request.
- Write a one page artifact that fits your pattern.
- Run it through the rubric.
- Compare your version to a stronger version from the model and notice what you missed.
That is it. That is the smallest useful practice loop.
You are no longer “doing your reps” only in live games with fuzzy, delayed feedback. You have a practice lane that is cheap, repeatable, and specific to your real work.
Rubrics without surveillance #
Rubrics and AI scoring are powerful and dangerous.
If you are not careful, this can drift from “practice tool” to “metric that gets weaponized.”
Guardrails:
- Rubric scores are coaching signals, not performance ratings.
- No secret scoring. If the AI is grading docs, people should know and see the output.
- Keep the rubric small and human readable. If you cannot explain it to a new hire in five minutes, it is too ornate.
- Rotate who maintains the rubric so it does not harden into one person’s taste.
This is the same pattern as metrics. Once a number can travel up a slide deck, it will try to become the story. You have to guard the intent.
Why we put this Doctrine Companion under Doctrine 09: Decision Altitude #
Decision Altitude asks “what level of the sky are we flying at” when we make a call.
Artifacts Over Adjectives adds a sharper question:
At this altitude, what should a good artifact look like, and how can we practice producing it on purpose.
A senior leader should not just be strategic. They should leave behind visible artifacts of strategic judgment that someone else can read a year later and say “this is why we chose that path, and here is where we would update it now.”
If you can name the skill, see it in the artifact, grade it with a clear rubric, and practice it in a safe lane, then you have something most organizations never get.
You are no longer arguing about adjectives. You are coaching on film.
Field notes and examples #
- Field Note: The Stamp Fallacy at the Interface
- Field Note: The Benchtop Fallacy: Why Inventory Is Not Capability
- Decision Altitude: Why Tool Expertise Does Not Confer Outcome Authority
- Documentation Makes Operational Judgment Inspectable
- The Audition Trap: Why Panel Interviews Create False Negatives in Hiring
Last Updated on February 21, 2026