Doctrine claim: Loop closure is not about politeness; it is about physics. In any system (digital or human) an open loop consumes resources (memory, attention, bandwidth). This guide defines Acknowledgment as Infrastructure: the specific protocols required to clear cognitive RAM and enable high-tempo coordination without burnout. Loop closure turns intent into coordinated action by freeing attention and preventing silent failure.
TL;DR: How To Use This Guide #
If you remember nothing else, remember this
Most teams fail because they treat everything like a bullhorn announcement instead of a radio check.
- Bullhorn mode: “I said it once, everyone surely heard.”
- Radio check mode: “I say it, I hear you say it back, then we move.”
CSMA is bullhorn mode.
CSMA/CD and CSMA/CA are radio checks with different levels of strictness.
For anything that changes risk, money, or someone else’s schedule, you need a radio check.
This is not a standard article. It is a technical manual for human coordination. It bridges the gap between Network Engineering (how computers talk) and Team Dynamics (how people talk).
If you only have 3 minutes, start here:
The Core Principle: “Unverified message receipt is an open failure mode.” If you send a message and don’t get an acknowledgment, you haven’t communicated. You have just added noise.
The Tool: Use the Protocol Escalation Framework below. Stop guessing whether to just “say it” or “verify it.” Match the protocol to the stakes.
How to Navigate:
- Read “Technical Concepts” to learn the vocabulary (CSMA vs. CD vs. CA).
- Jump to “The Escalation Framework” to see the decision logic.
- Use “Practical Implementation” to fix your team or household tomorrow.
You do not need to be an engineer to use this. You just need to be tired of repeating yourself.
Foundational Principle #
Unverified message receipt is an open failure mode.
When a message is sent but not acknowledged, the system enters an undefined state. The sender cannot know if the message was received, understood, or lost. This uncertainty creates three immediate costs: interrupt cycles (the sender must stop to verify), working memory load (the sender must track “did they hear me?”), and degraded federation capacity (actors cannot operate independently without trusted handoffs).
Loop closure is not politeness protocol. It is system infrastructure that determines whether distributed actors can coordinate effectively under pressure.
This principle comes from three domains that have spent decades solving coordination problems under high stakes: radio frequency communications, aviation operations, and emergency medicine. When lives and missions depend on coordination, you learn what works. What works is verified message receipt.
I’ve experienced these failures across multiple domains. In the cockpit when workload is high (weather, traffic, non-standard procedures), the last thing you can afford is uncertainty about whether your copilot heard your callout. In emergency medicine during Hurricane Katrina and Hurricane Florence deployments, you cannot carry “did that paramedic understand triage assignment?” in your head while you’re trying to assess the next patient. And at home during morning rush with multiple kids in a sprawling 1790 farmhouse, unacknowledged messages stack up until something breaks.
The pattern is consistent: high-stakes environments force tight protocols. But those protocols must be built in safe containers, not invoked only during emergencies.
Technical Concepts in Day-to-Day Context #
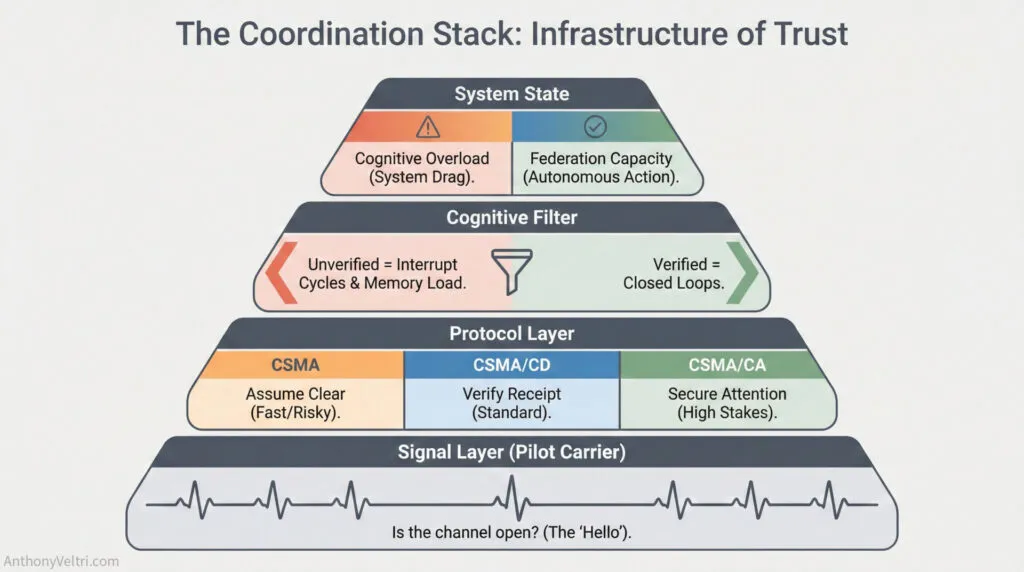
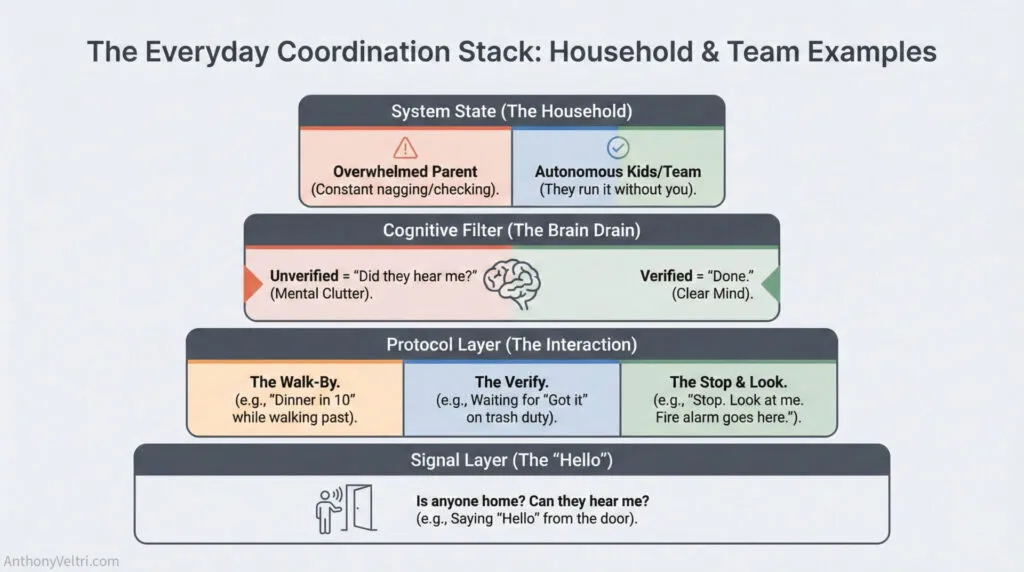
The technical precision matters because these concepts have been tested under pressure. But you don’t need an RF engineering background to apply them. Here’s what these terms mean in everyday life:
Pilot Carrier #
In RF systems: A pilot carrier is a reference signal that proves the communication channel is working before you send real data. It’s the “heartbeat” that says “I’m here, you’re there, we can communicate.”
In day-to-day life: It’s the “hello” you say when entering a room to confirm someone can hear you. Or saying someone’s name before giving them instructions. You’re testing whether the channel is open before sending the actual message.
Example: You walk in the front door and say “hello.” If no one responds and you know that sound should reach the kitchen, you now know either no one’s home or they’re in a noise-isolated space. You’ve tested the channel before trying to communicate anything important. Without that test, you might waste time calling out instructions to an empty house or to someone who’s wearing headphones and can’t hear you.
In my house, I know the acoustics precisely. When I say “hello” from the front door, that sound should reach the kitchen, living room, and upstairs landing if doors are open normally. If no one responds and I know someone’s home, I now know they’re either in the basement with the door closed, wearing headphones, or deeply focused and not attending to environment. I’ve tested the pilot carrier. Channel is either not available or requires stronger signal.
CSMA (Carrier Sense Multiple Access) #
In networking: This means you send data assuming the channel is clear, without waiting for confirmation. You’re trusting the environment.
In day-to-day life: You say something while walking past someone and just assume they heard you. No acknowledgment required or expected. It is also the operating logic of the phone in your pocket: every time you connect to Wi-Fi, your device silently listens for a micro-second gap in the radio waves before it dares to transmit, ensuring your data gets through without crashing the network.
Example: Walking past your kid’s room, saying “dinner in 10 minutes” without stopping or waiting for response. You’re assuming the message landed. This works fine for low-stakes information but creates problems when stakes increase.
CSMA/CD (Collision Detection) #
In networking: You send the message but monitor briefly to see if it was received, and re-send if needed. You’re checking for delivery confirmation.
In day-to-day life: You say something but pause long enough to hear “got it” or “okay.” If you don’t hear acknowledgment, you know to check.
Example: “Take out the trash.” You keep moving but listen for “got it.” If you don’t hear it within 2-3 seconds, you stop and verify. This is the standard mode for moderate-stakes household coordination.
CSMA/CA (Collision Avoidance) #
In networking: You explicitly coordinate before sending to avoid any chance of message loss. You’re securing the channel before using it.
In day-to-day life: You make sure you have someone’s full attention before speaking, and get explicit confirmation they understood.
Example: “Stop what you’re doing. Look at me. Here’s what needs to happen next.” You establish attention, deliver message, wait for verbal confirmation before proceeding. This is appropriate for high-stakes or time-critical coordination.
Federation Capacity #
In systems architecture: This is how many semi-independent actors can coordinate with minimal central supervision. High federation capacity means distributed actors can operate effectively without constant oversight.
In day-to-day life: How many people can operate on their own without you constantly checking on them. If you can delegate a task with verified handoff and trust it’ll get done, that’s high federation capacity. If you have to check repeatedly, that’s low federation capacity forcing tighter supervision.
Example: If you can tell your teenager “take care of the dog – food, water, walk” and trust it’ll happen, you have federation capacity. If you have to check each sub-task, you don’t. Which means you can’t delegate effectively and everything requires your direct oversight. The system doesn’t scale.
Interrupt Cycle #
In computing: An interrupt stops current processing to handle something urgent, then resumes. The cost is not just the interruption itself but the full context switch.
In day-to-day life: Having to stop what you’re doing to verify something you thought was handled. The cost isn’t just the verification – it’s stopping your current task, switching context, verifying, then restarting what you were doing.
Example: You’re working on a report. You remember you’re not sure if your kid heard you about trash. Now you have to: save document, get up, find kid, verify, return to desk, remember where you were in the report, resume. That full cycle is the interrupt cost. Do that three times in an hour and your actual work grinds to a halt.
For complex cognitive work, the re-establishment time after an interrupt can be 10-15 minutes. You’re not just spending 30 seconds verifying – you’re spending 30 seconds plus the time it takes to rebuild your mental model of what you were doing. Three interrupts can effectively kill an hour of productive work.
Working Memory Load #
In cognitive science: Working memory is your active attention capacity – how many things you can keep track of simultaneously. It’s limited, usually to about 3-7 items.
In day-to-day life: All the “I need to remember to check on X” items you’re carrying in your head. Each unverified message (“did they hear me?”) occupies a slot.
Example: You’re trying to make dinner while remembering that you told son about trash (did he hear?), daughter about homework (did she start?), and spouse about picking up groceries (did they see the text?). Three slots are burning capacity that should be available for cooking. When working memory fills up, you start dropping tasks or making errors.
CRM (Crew Resource Management) #
In aviation: CRM is the formal framework for using all available resources (people, information, equipment) to achieve safe flight. When CRM capacity is exceeded, performance degrades rapidly.
In day-to-day life: Your total capacity to manage multiple tasks, coordinate with multiple people, and maintain situational awareness simultaneously. When you exceed CRM capacity, things start breaking.
Example: Getting three kids ready for school while packing lunches, answering work emails, and remembering dentist appointment. When too many things are in flight with unverified handoffs, you hit CRM limit. Something gets dropped. High-functioning people hit this limit too – it’s a capacity constraint, not a competence issue.
The failure threshold is rapid: when CRM capacity is exceeded, system performance degrades nonlinearly. This is why cockpit procedures and emergency medicine protocols demand explicit acknowledgment – they’re operating near CRM limits already. There’s no spare capacity for carrying “did they hear me?” questions.
With these concepts grounded, we can examine how they interact to create or prevent coordination failures.
The Three-Dimensional Cost Structure #
Unverified message receipt creates costs across three dimensions. The first dimension is most visible. The third is most consequential.
Dimension 1: Direct Operational Costs (Most Visible) #
Interrupt Cycle Cost
Every unacknowledged message forces the sender into verification mode. The cost is not just the verification itself but the full interrupt sequence:
- Suspend current task
- Context switch to verification mode
- Execute verification
- Resume previous task
- Re-establish working context
In a 10-message environment where 3 messages go unacknowledged, you’re executing 3 full interrupt cycles. Each cycle carries setup and teardown overhead beyond the verification time itself.
This is why “just go check” is expensive advice. You’re not just spending 30 seconds checking. You’re spending 30 seconds checking plus however long it takes to get back into the flow of what you were doing. For complex cognitive work, that re-establishment time can be 10-15 minutes.
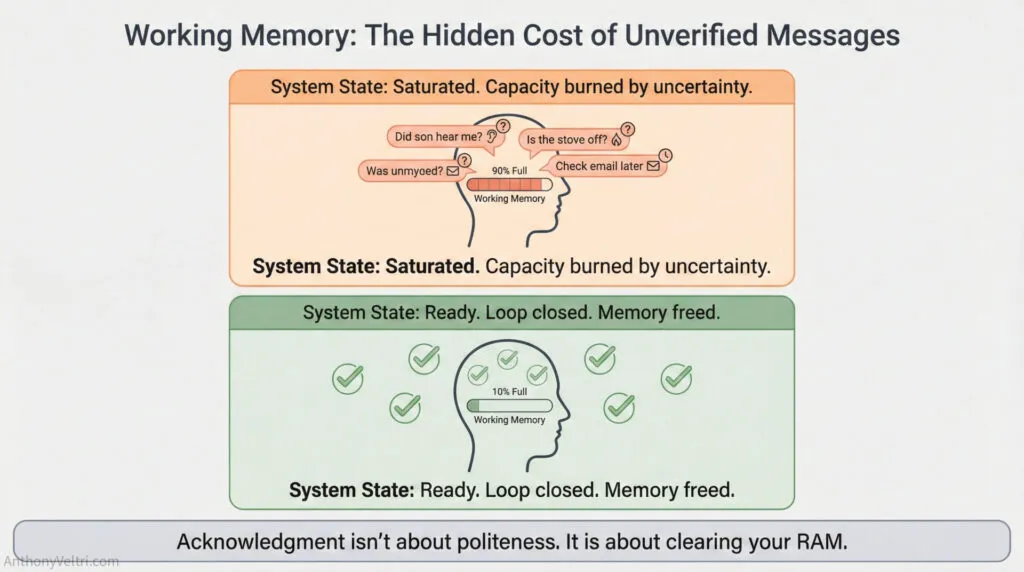
Working Memory Load
If the sender chooses not to interrupt immediately, unacknowledged messages remain in active memory. “Did son hear me about trash?” occupies a working memory slot while you’re trying to execute other tasks. Three unacknowledged messages mean three slots burning capacity.
The failure threshold is rapid: when crew resource management (CRM) capacity is exceeded, system performance degrades nonlinearly. This is why cockpit procedures and emergency medicine protocols demand explicit acknowledgment – they’re operating near CRM limits already. There’s no spare capacity for carrying “did they hear me?” questions.
I’ve experienced this in multiple domains. In the cockpit, when workload is high (weather, traffic, non-standard procedures), the last thing you can afford is uncertainty about whether your copilot heard your callout. In emergency medicine during mass casualty events, you cannot carry “did that paramedic understand triage assignment?” in your head while you’re trying to assess the next patient. And at home during morning rush with multiple kids, unacknowledged messages stack up until something breaks.
Dimension 2: Container and Interface Dynamics #
The Safe Container Problem
Comfortable environments (home, familiar workspaces) breed protocol sloppiness. When consequences are distant or invisible, actors default to CSMA mode (assume message delivered) regardless of actual delivery reliability.
My children demonstrate this perfectly. In our house – which is fairly sprawling, 1790 farmhouse with multiple levels and rooms – they’ll speak softly to themselves when I give them instructions. “Mm-hmm” muttered while they’re focused on something else. At home, consequences feel distant. Trash not taken out? We’ll deal with it later. Message not heard? Dad will come back and check.
But in a busy city environment, their acknowledgment protocol tightens dramatically. When I say “stay close” or “watch for cars,” I get clear, immediate “got it” responses. Not because I’ve suddenly become more authoritarian, but because the consequences are immediate and visible. In the city, protocol failures have fast feedback loops.
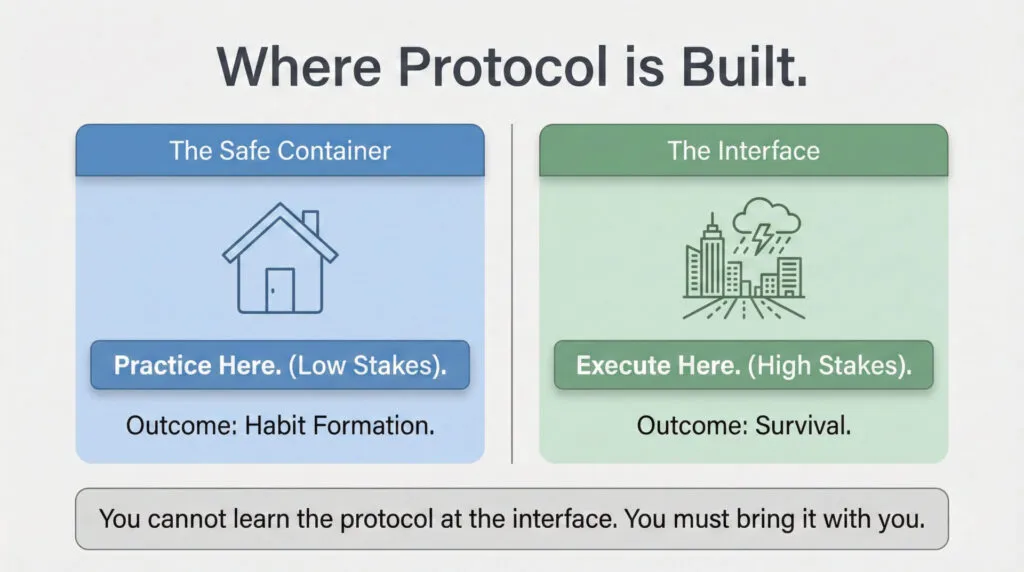
This is the safe container problem: you can’t learn tight protocols AT the interface. They must be practiced in safe containers. If my kids only practice clear acknowledgment when we’re in dangerous environments, they won’t have the habit ingrained. The protocol has to be steady-state infrastructure, not emergency-only behavior.
The Interface Exposure
Systems break at interfaces. Container boundaries (home to street, office to field, planning to execution) expose protocol weaknesses that were hidden inside safe containers.
You see this in organizational contexts constantly. Team has loose coordination protocols internally – works fine because everyone’s co-located, can see each other, can clarify in real-time. Then they have to coordinate with external team across time zones using email. Suddenly, the loose protocols create massive delays and misunderstandings. The interface exposed the weakness.
This is the stewardship principle again: understanding why the tool was designed that way before you need it under pressure. The scythe’s blade angle makes sense when you understand grain harvest at scale (not just cutting your small garden). Loop closure protocols make sense when you understand coordination under load (not just calm household operations).
Dimension 3: Federation Capacity (Least Visible, Highest Impact) #
Tight Protocols Enable Loose Coupling
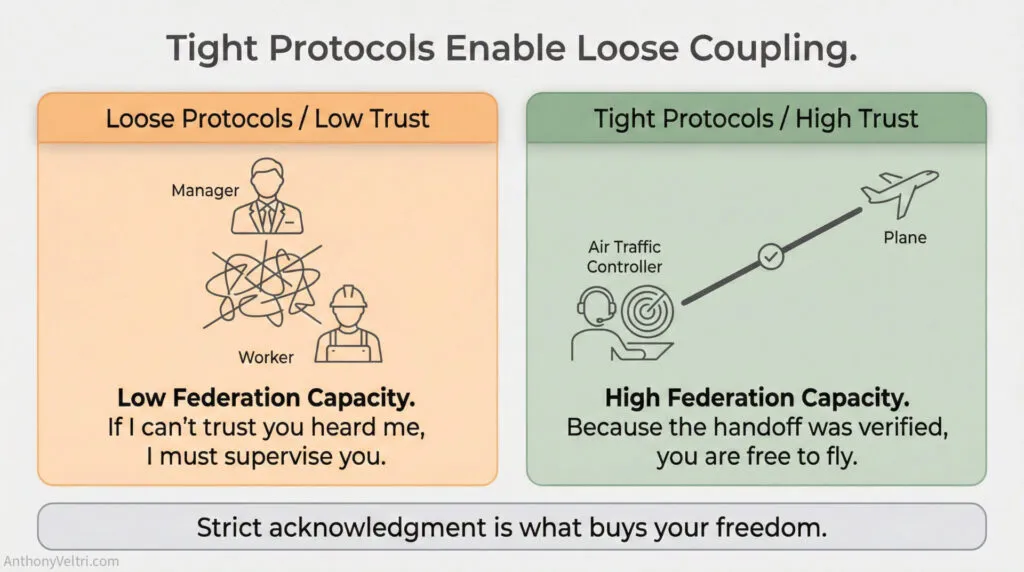
This is the counterintuitive insight: strict acknowledgment requirements enable independence, not constraint.
If I can trust that when I hand something off with verified receipt, it’s actually been received and understood, I can move to the next task without supervision. I can operate semi-independently because the handoff was clean. I’m not burning working memory wondering if the message landed. I’m not planning interrupt cycles to verify. I’ve closed the loop and moved on.
But if I can’t trust receipt, I’m forced into tighter integration. I must hover, check repeatedly, supervise. I can’t delegate effectively because delegation without verified handoff means I still own the task. Loose protocols force tight coupling. The system that seems “more relaxed” about acknowledgment actually requires more oversight.
Aviation demonstrates this at scale. Multiple aircraft operating in the same airspace with minimal direct supervision. How? Because every handoff is verified. “Cessna 19 Echo, Runway 34 Left, cleared to land.” “Roger, Runway 34 Left, Cessna 19 Echo.” That exchange isn’t radio tradition or military formality. It’s the infrastructure that lets the tower controller manage 20 aircraft without needing to visually verify that each one understood their clearance.
The controller clears an aircraft to land and gets read-back confirmation. Loop closed. Controller’s working memory is freed. Controller can now coordinate the next aircraft. Without that verified acknowledgment, the controller would need to either: (a) visually confirm the aircraft is complying, which doesn’t scale beyond a few aircraft, or (b) carry “did 19 Echo hear me?” in working memory, which rapidly exceeds CRM capacity.
Emergency medicine works the same way. During Hurricane Katrina response, I saw incident command systems managing hundreds of personnel across geographic areas. How? Verified handoffs. “Strike Team 1, move to Anchor Point Charlie.” “Strike Team 1 copies, moving to Anchor Point Charlie.” Loop closed. Incident commander doesn’t need to send someone to physically verify the team is moving. The IC has federation capacity – distributed teams operating with minimal direct supervision.
During Hurricane Florence, I watched this play out again. ICS system under strain, multiple agencies, radio systems at capacity. Teams that maintained tight loop closure maintained effectiveness. Teams that used loose protocols created coordination failures that consumed supervision capacity. The ones who understood loop closure as infrastructure could scale operations. The ones who treated it as formality hit coordination limits fast.
Without tight loop closure, you cannot federate. You’re forced into integration (constant supervision, tight coupling). The acknowledgment protocol isn’t bureaucracy. It’s what enables the system to scale.
The Escalation Framework: Protocol Selection and Cost Structure #
Once you see CSMA, CSMA/CD, and CSMA/CA as different levels of “how sure are we that the message landed,” you can start making intentional choices. At work, the easiest place to feel this is in email.
How to translate this in email:
- CSMA: FYI email. No reply expected. If they miss it, nothing breaks.
- CSMA/CD: “Please reply ‘got it’ so I know this landed.”
- CSMA/CA: “I need explicit yes or no by [time]. If I do not hear from you, I will assume [default].”
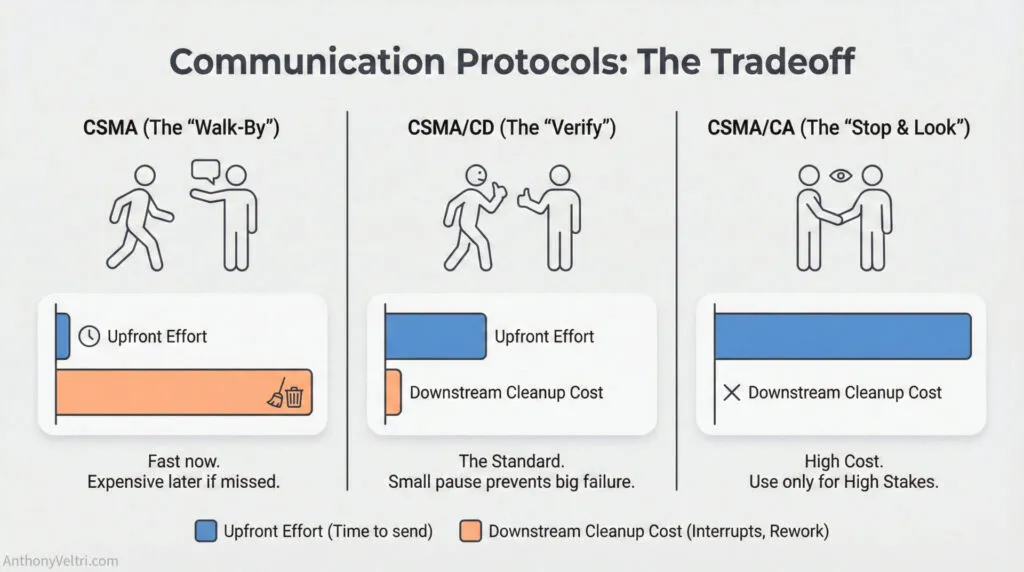
Communication protocols exist on a spectrum from lowest-overhead (CSMA) to highest-reliability (CSMA/CA). Each step trades efficiency for certainty. Wrong selection creates either message loss or coordination bottleneck.
CSMA: Carrier Sense Multiple Access (Assume Channel Clear) #
Mechanism: Send message, assume delivery, continue immediately.
Cost Structure:
- Near-zero sender overhead
- Maximum throughput
- No verification burden
- Minimal attention required
Risk Profile:
- High message loss rate
- Creates downstream interrupt cycles OR working memory burden
- Sender owns failure if message not delivered
- Compounds in multi-actor environments
Best For:
- Low-stakes information (“Weather looks nice today”)
- Slow-paced environments
- Single-actor systems
- Asynchronous contexts where delayed confirmation is acceptable
Failure Mode: You believe message was delivered. It wasn’t. Task doesn’t get done. You discover failure later at higher cost.
The illusion is that CSMA mode is efficient. It looks fast because there’s no acknowledgment overhead. But that’s throughput illusion. The efficiency is front-loaded. The cost shows up downstream when you discover the message never landed and now you’re executing expensive interrupt cycles or worse, dealing with task failure consequences.
Example Recognition Pattern:
“I told everyone at dinner we’re leaving early tomorrow for the airport.” No acknowledgments. Just continued conversation. Next morning: chaos. No one is ready. Everyone thought they heard “early” but didn’t internalize it. Now you’re dealing with rushed packing, stress, potential missed flight.
The CSMA failure happened at dinner. The cost materialized in the morning rush. That time lag makes it hard to connect cause and effect, which is why people keep using CSMA in inappropriate contexts.
CSMA/CD: Carrier Sense Multiple Access with Collision Detection #
Mechanism: Send message, monitor for acknowledgment, verify receipt or escalate.
Cost Structure:
- Moderate sender overhead per message
- Must maintain attention through brief acknowledgment window (usually 2-3 seconds)
- Small time cost per transaction
- Scales reasonably in moderate-traffic environments
Risk Profile:
- Medium – catches most failures
- Requires sender to stay in loop long enough to detect acknowledgment
- If no acknowledgment arrives, must escalate or create interrupt cycle
- Sender must decide: wait for acknowledgment or move on?
Best For:
- Moderate-stakes coordination
- Moderate traffic environments
- When sender can afford brief monitoring window
- Household operations, standard work handoffs, most professional coordination
Failure Mode: Acknowledgment doesn’t arrive. Now sender must choose: interrupt cycle to verify, or carry working memory load. You’ve prevented some failures but not all.
This is steady-state protocol for most functional teams and families. It’s the sustainable middle ground. Slight overhead per message, but prevents most downstream failures.
Example Recognition Pattern:
Walking past son: “Take out trash.” Keep walking, listening for “got it.”
Scenario A: You hear “got it” within 2 seconds. Loop closed. You continue to next task with clear working memory.
Scenario B: You don’t hear anything. Now you either stop and turn back (interrupt cycle), or you add “verify trash” to working memory. Either way, the acknowledgment failure created immediate cost.
The key is that CD mode reveals failures quickly. You know within seconds whether the loop closed. CSMA mode lets failures hide until much later.
CSMA/CA: Carrier Sense Multiple Access with Collision Avoidance #
Mechanism: Establish attention explicitly before sending message. Confirm receipt before proceeding.
Cost Structure:
- High coordination overhead
- Must secure attention before message
- Explicit confirmation required
- Significant time cost per transaction
- Can strangle throughput in high-message environments
Risk Profile:
- Very low message loss
- Nearly eliminates delivery failures
- But creates bottleneck in fast-paced or high-volume contexts
- Over-use degrades system flow
Best For:
- High-stakes decisions
- High-consequence tasks
- When prior protocol failed
- Critical handoffs (surgery, aviation emergencies, tactical operations)
- Container boundaries (entering dangerous environments)
Failure Mode: Rarely fails on delivery, but overuse creates coordination bottleneck. System becomes unable to process message volume. Everyone’s exhausted by communication overhead.
CA mode is appropriate when stakes justify overhead. But using CA mode for everything creates a different failure: coordination becomes so expensive that people start skipping it. You’ve created protocol overhead fatigue.
Example Recognition Pattern:
Emergency situation. Fire alarm. Multiple kids, need to evacuate.
“Everyone stop. Look at me.” Wait for visual attention from each person. “We’re evacuating now. Front door. Meet at the oak tree. Tell me back where we’re meeting.”
Each person: “Oak tree.”
“Go.”
High overhead. But appropriate for stakes. The coordination time is worth it to ensure no one misunderstands the rally point. This is not the protocol for “dinner’s ready.” This is the protocol for “the house might be on fire.”
The Compounding Cost Problem #
The protocol costs aren’t linear. They compound based on message volume, actor count, and failure rate.
In a 10-message, 3-actor scenario:
CSMA mode:
- 10 fast sends (minimal time investment)
- 3-4 messages lost (typical failure rate in noisy environment)
- Creates 3-4 interrupt cycles later OR 3-4 working memory slots burning continuously
- Total cost: 10 quick sends + 3-4 expensive interrupts later + downstream task failures
- Throughput illusion: looks fast initially, very expensive downstream
CSMA/CD mode:
- 10 sends with brief acknowledgment monitoring (2-3 seconds each)
- 1-2 messages require re-send or escalation
- Moderate cost per message, but prevents most downstream failures
- Total cost: 20-30 seconds of acknowledgment overhead, minimal downstream repair
- Sustainable throughput: steady state efficiency that scales
CSMA/CA mode:
- 10 explicit attention establishments + confirmations
- Very high time cost upfront (could be 5-10 minutes total)
- Nearly zero downstream failures
- Total cost: Very slow message processing, but only appropriate for critical items
- Appropriate for high stakes, unsustainable for routine operations
The critical insight: CSMA looks efficient until you account for downstream costs. CD looks like overhead until you compare it to interrupt cycles. CA looks expensive until you’re in a life-safety situation where message loss is unacceptable.

Decision Tree: Protocol Selection #
START: You need to communicate information to another actor
Question 1: What are the consequences if this message is not received?
- Minimal/None → CSMA (example: “Weather looks nice today”)
- Moderate → Go to Question 2
- Severe → CSMA/CA (example: “Do not enter that room, gas leak suspected”)
Question 2: What is the pace of operations?
- Slow/Relaxed → CSMA/CA acceptable (you can afford coordination overhead)
- Moderate → Go to Question 3
- Fast → CSMA/CD (CA would strangle throughput)
Question 3: Is this a routine operation in a known environment?
- Yes → CSMA/CD (standard acknowledgment protocol)
- No → CSMA/CA (new territory requires explicit coordination)
Question 4: Has the receiver demonstrated reliable acknowledgment patterns?
- Yes → CSMA/CD (trust established, standard protocol sufficient)
- No → CSMA/CA (must establish protocol before trusting CD mode)
Override Condition:
If you’re at a container boundary (home to city, office to field, planning to execution), escalate one level from default selection. Interfaces require tighter protocols than interior operations.
Example: Standard household task delegation uses CD mode. But when leaving house for busy city, shift to CA mode temporarily: “Okay, we’re entering high-traffic area now. When I say stay close, I need to hear ‘got it’ immediately. Understood?” Get explicit confirmation of the protocol before entering the interface.
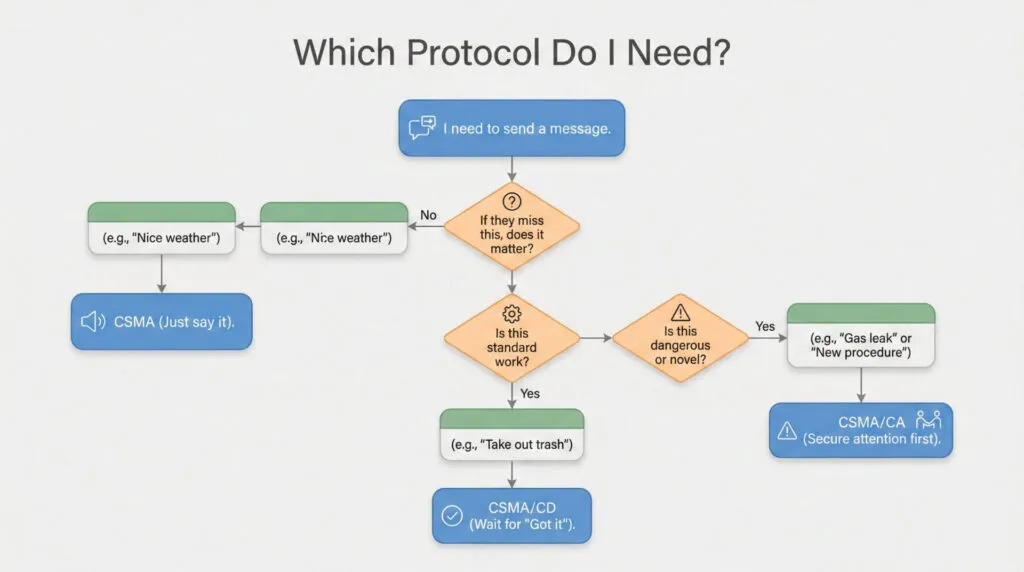
Note on Protocol Selection as Pattern Recognition:
This decision tree formalizes what experienced coordinators do intuitively. With practice, you stop consciously running through questions and start recognizing patterns: “This feels like a CA situation” or “Standard CD mode should work here.” That’s Recognition-Primed Decision Making (RPDM) in action – your brain is rapidly assessing multiple cues (stakes, pace, trust, environment) and pattern-matching to prior experiences.
New coordinators benefit from the explicit decision tree. Experienced coordinators are running Bayesian updates based on immediate evidence: “I asked for CD acknowledgment, didn’t get clear response, environment is noisy – update probability that message landed, escalate to CA.” For more on how pattern recognition enables rapid decisions under uncertainty, see Doctrine 22: When “It Depends” is the Right Answer.
Domain Examples #
Aviation: Tower-to-Aircraft Communication #
Scenario: Aircraft approaching for landing
CSMA Failure:
Tower: “Cessna 19 Echo, Runway 34 Left, cleared to land.”
Pilot: [Says nothing, or nods in cockpit where tower can’t see]
Result: Tower doesn’t know if clearance was received. Cannot clear next aircraft. Must re-transmit or wait. Creates coordination bottleneck and safety risk. If tower assumes message was received and clears another aircraft, you now have potential conflict on runway.
CSMA/CD Standard:
Tower: “Cessna 19 Echo, Runway 34 Left, cleared to land.”
Pilot: “Roger, Runway 34 Left, Cessna 19 Echo.”
Result: Loop closed. Tower knows clearance received and understood. Can proceed with next coordination. Multiple aircraft can operate in same airspace because handoffs are verified. Tower controller’s working memory is freed – doesn’t need to track “did 19 Echo hear me?” while coordinating five other aircraft.
The read-back includes the critical details (runway number, aircraft ID). This isn’t just “roger” – it’s verification that the specific instruction was understood. Tower can immediately catch errors: if pilot reads back wrong runway, tower can correct before aircraft is on final approach.
CSMA/CA Application:
Emergency situation, multiple aircraft, non-standard procedures.
Tower: “All aircraft, stop transmitting. Cessna 19 Echo, confirm you are listening.”
Pilot: “19 Echo, listening.”
Tower: “19 Echo, emergency traffic on runway, go around immediately, climb and maintain 2000.”
Pilot: “Going around, climbing to 2000, 19 Echo.”
Tower: “Correct, report turning crosswind.”
Result: Explicit attention secured before critical instruction. No ambiguity. Stakes are high (potential collision), so protocol escalates to CA mode. Higher coordination overhead justified by immediate safety risk.
Why This Protocol:
High-stakes, high-pace, distributed operations. Multiple actors sharing same airspace. Federation capacity requirement is extreme – tower cannot possibly provide direct supervision to every aircraft. Controller might be managing 20+ aircraft simultaneously.
Tight loop closure enables aircraft to operate semi-independently with minimal tower supervision. Without verified acknowledgment, tower would need constant visual confirmation (impossible in weather, impractical at scale) or severely reduced traffic (economically unviable, would cripple air transportation system).
The protocol has been refined over decades through accident investigation. Every “pilot acknowledged wrong runway” accident led to tighter read-back requirements. The current system represents learned experience, paid for in failures.
Home: Household Task Delegation #
Scenario: Parent needs trash taken out before leaving for school
CSMA Failure:
Parent walking past: “Take out the trash.”
Child: [Says “okay” quietly to self, or nods while focused on tablet]
Result: Parent doesn’t hear acknowledgment. Now parent must either:
- Stop, turn around, verify (interrupt cycle – costs 30 seconds plus context switch)
- Add “check trash” to working memory (cognitive load – burns attention slot)
- Assume it’s handled and discover failure later (downstream cost – trash doesn’t go out, consequences tomorrow)
This scenario plays out in my house regularly. I’ll walk past, say something, and get a mumbled response I can’t hear. Now I’m carrying “did he actually hear me?” while I’m trying to do three other things. Or I stop, come back, and verify – which means I’ve lost flow on whatever I was doing.
CSMA/CD Standard:
Parent walking past: “Take out the trash.”
Child: “Got it.” [Loud enough to hear from hallway]
Result: Loop closed. Parent clears item from working memory. Can continue with next task. Child has acknowledged responsibility. If trash doesn’t get done, parent knows child heard and either forgot or chose not to do it (different failure mode, different response – this is about follow-through, not about communication).
The key is volume and clarity. Not shouting, but speaking clearly enough that the sender can hear from their position. This respects the sender’s need to continue moving while confirming the loop closed.
CSMA/CA Application:
Morning of important event, running late, high stress.
Parent: “Stop. Look at me.” [Wait for visual attention] “Three things before we leave: shoes on, backpack by door, trash out. Tell me back what you’re doing.”
Child: “Shoes, backpack, trash.”
Parent: “Good. Go. Five minutes.”
Result: Explicit coordination under time pressure. Higher overhead justified by stakes (can’t be late to this event) and pace (compressed timeframe). The read-back ensures instructions were understood, not just heard.
Protocol Flexibility Example:
The protocol isn’t rigid. It shifts based on context:
- Start of school year: CSMA/CA mode (establishing protocols, teaching loop closure, building habits)
- Mid-year, proven track record: CSMA/CD mode (standard acknowledgment, steady state operations)
- Morning routine when rushed: CSMA/CA (stakes and pace require explicit coordination)
- Casual weekend, low stakes: CSMA acceptable for low-stakes items (“Lunch is ready” can be CSMA)
The protocol flexibility is important. Not everything needs explicit confirmation. But the family needs to understand when protocol shifts and why. That’s part of teaching the system, not just compliance with individual instructions.
Why This Protocol:
Home is a safe container that breeds protocol sloppiness. Consequences feel distant. “I’ll just come back and check” seems cheap because you’re not tracking the interrupt cost. Working memory burden isn’t visible like a broken bone.
But without practicing CD mode in low-stakes home environment, family will fail at interfaces. Take that same family to busy city, travel day with tight connections, or emergency situation – the protocol won’t be there. You can’t invoke tight coordination when you need it if you haven’t built the habit when you didn’t need it.
The protocol isn’t about control or authority. It’s about building infrastructure that works when stakes increase. My kids don’t acknowledge clearly because I demand obedience. They acknowledge clearly because they understand I need to clear that item from my working memory so I can help them with the next thing. That’s the frame that makes sense to them.
NWCG/Disaster Response: Incident Command Coordination #
Scenario: Division supervisor coordinating with multiple strike teams during wildland fire
CSMA Failure:
Radio: “Strike Team 1, move to Anchor Point Charlie.”
[No response, or response blocked by other radio traffic]
Result: Division supervisor doesn’t know if message received. Strike Team 1 may not be moving. Supervisor must now:
- Re-transmit (uses limited radio channel, delays other coordination)
- Physically verify (requires supervisor to leave position or send runner – wastes resources)
- Assume compliance (creates safety risk if team didn’t hear and doesn’t move)
In disaster response, radio channel congestion is constant. If you don’t get acknowledgment, you don’t know if message was lost to congestion, if radio failed, if team is in bad coverage area, or if they’re not listening. That uncertainty cascades – you can’t make next coordination decision without knowing if first instruction landed.
CSMA/CD Standard:
Radio: “Strike Team 1, Ops, move to Anchor Point Charlie.”
Strike Team 1: “Strike Team 1 copies, moving to Anchor Point Charlie.”
Result: Message confirmed. Supervisor knows movement is happening. Can coordinate next resource. Federation capacity maintained – multiple teams operating with minimal supervision because handoffs are verified.
The acknowledgment includes the instruction (not just “roger”). If Strike Team 1 heard wrong location, supervisor catches it immediately: “Negative, Anchor Point Charlie, not Bravo.” Prevents team from moving to wrong location.
CSMA/CA Application:
Fire behavior change, immediate threat, crews in hazard zone.
Radio: “All units on Division Alpha, this is Division Alpha, acknowledge receipt.”
[All units acknowledge individually – verifies everyone heard alert]
Radio: “Be advised, spot fire across line creating escape route concern. All units prepare to disengage per LCES. Strike Team 1, acknowledge.”
Strike Team 1: “Strike Team 1 copies, spot fire, escape route concern, prepared to disengage per LCES.”
Radio: “Correct. Strike Team 2, acknowledge.”
[Continue through all units]
Result: Life safety situation. Explicit confirmation that critical information received and understood by every team. Higher coordination overhead (takes 2-3 minutes to go through all units) justified by immediate risk. This is CA mode – securing acknowledgment before assuming anyone can proceed.
Why This Protocol:
Disaster response operates under high stakes, distributed command, and often degraded communication infrastructure. Radio channels are limited resources – dozens of teams sharing same frequencies. Unverified messages create safety risks and coordination failures that compound rapidly.
The ICS (Incident Command System) demands explicit acknowledgment because federation capacity is required. Incident commander cannot directly supervise hundreds of personnel across geographic area. Span of control for supervisor is 3-7 resources – but those resources are themselves supervising more resources. It’s federation stacked on federation.
Verified loop closure is the infrastructure that enables span of control. Without it, supervisors spend all their time verifying whether instructions landed instead of making next tactical decision. The system collapses under its own coordination overhead.
I learned this during Hurricane Katrina and saw it confirmed during Hurricane Florence. The teams that maintained protocol discipline could scale operations. The teams that used loose protocols hit coordination limits fast. You’d have a supervisor managing three strike teams, and if those strike teams didn’t acknowledge clearly, the supervisor was burning all their attention tracking “did Team 1 understand? Did Team 2 hear me?” instead of watching fire behavior and adjusting strategy.
Federal Register: Notice and Comment Process #
Scenario: Federal agency proposing new regulation, seeking public input
CSMA Failure (Historical Problem):
Agency publishes notice in Federal Register.
Public may or may not see it (distribution was physical newspapers, limited circulation).
Comments submitted via mail may or may not arrive.
Agency has no confirmation loop – if comment was lost in mail, no one knows.
Result: Legitimacy challenges, claims of inadequate notice, litigation risk. “We submitted comments but you claim you never received them.” No way to verify. This created years of legal challenges to rulemaking processes.
CSMA/CD Standard (Current System):
Agency publishes notice in Federal Register with docket number.
Public submits comments through Regulations.gov (electronic system).
System generates confirmation receipt with tracking number immediately upon submission.
Commenter has proof of submission (tracking number, timestamp, copy of comment).
Agency has verified record of all comments received.
Result: Loop closed on submission. Both parties know comment was delivered. Reduces litigation risk over “we submitted but you claim you didn’t receive.” The confirmation receipt is the acknowledgment – commenter doesn’t need to wonder if comment was lost.
This is CD mode at administrative scale. System confirms receipt automatically. No human intervention needed for acknowledgment. The infrastructure handles loop closure.
CSMA/CA Application:
Controversial rule with major stakeholder disagreement, litigation anticipated.
Agency holds public meetings (not just written comments – escalating to synchronous communication).
Verbal comments recorded by court reporter.
Agency reads back commenter’s name and affiliation after each comment.
Transcript provided with meeting record showing exact words spoken.
Multiple verification layers: verbal acknowledgment, court reporter record, published transcript.
Result: Multiple verification layers. Reduces ambiguity about what was said and who said it. Much higher overhead (public meetings are expensive, court reporters cost money, transcription takes time) justified by controversy level and litigation likelihood.
When stakes are high enough, even government shifts to CA mode. The overhead is worth it to prevent downstream legal challenges.
Why This Protocol:
Rulemaking is a federation system at massive scale. Agency cannot directly coordinate with every affected party – there might be thousands or millions of stakeholders. Notice and comment process allows distributed input without requiring individual outreach.
But legitimacy depends on verified delivery – both that notice was adequately provided AND that comments were received. The docket system with confirmation receipts is the loop closure infrastructure that enables administrative law to function at scale.
Without verified receipts, you’d have endless litigation over “did comment arrive?” The confirmation infrastructure prevents that failure mode. It’s not bureaucracy – it’s what makes the system scale.
The Vestigial Ritual Problem #
Loop closure protocols can become performative compliance divorced from understanding. This happens when the action (acknowledgment) is taught without the cost structure (why acknowledgment matters).
Oil Can Henry’s Example #
Oil change shop. Workers on top deck coordinating with workers below in service bay. They shout back and forth during oil changes: “Drain plug out!” “Drain plug out, roger!” “Filter off!” “Filter off, roger!”
If they understand WHY – coordination prevents injury (drain plug comes out, oil drains into pan below, person below needs to know when hot oil is coming), ensures no steps missed (if person above doesn’t hear acknowledgment, they know to verify), enables federation so manager doesn’t need to supervise every change – then the protocol works. It’s load-bearing infrastructure.
But if they’re just told “shout loud so manager can hear you working hard,” it becomes performative. They’re doing acknowledgment theater, not closing loops. The protocol survives only as long as manager is present enforcing it. As soon as supervision relaxes, protocol degrades because no one understands what breaks without it.
The first version scales. The second version requires constant enforcement.
Military Hooah Example #
“Heard, understood, acknowledged” – the three-part confirmation used in military contexts.
This can be taught as:
- (Performative) Speak loudly so your superiors can hear you comply with orders. It’s about demonstrating responsiveness and military bearing.
- (Functional) Close the loop so sender can clear item from working memory and move to next coordination. It’s about enabling distributed operations under pressure.
The first version creates compliance theater. Soldiers learn to be loud when officers are present. The protocol is about authority display.
The second version creates operational capacity. Soldiers understand that unacknowledged orders create either interrupt cycles (officer must verify) or working memory load (officer must track “did squad 2 hear me?”). The acknowledgment frees the officer to coordinate next element. That’s federation capacity – the officer can manage multiple squads because handoffs are verified.
I don’t have military experience, so I can’t say definitively how it’s taught. But I’ve been around enough military personnel to see both versions. The ones who understand the functional purpose maintain protocols even when no one’s watching. The ones who learned compliance maintain protocols only under supervision.
The Minimum Separation Distance #
How close can doing and understanding be before the practice loses meaning?
You must understand the cost you’re preventing before the action becomes meaningful.
A pilot who acknowledges clearances without understanding that unacknowledged clearances create coordination bottlenecks and safety risks is performing ritual. They’ll comply during training and checkrides but won’t maintain protocol when stressed or distracted.
An EMT who confirms patient handoffs without understanding that unverified handoffs create information loss and treatment errors is performing compliance. They’ll do it when supervisor is present but will skip it when busy.
A kid who says “got it” without understanding that unacknowledged messages create interrupt cycles for parents is performing obedience. They’ll do it when enforced but won’t maintain it when parents aren’t checking.
This is the stewardship principle again: understanding what the scythe’s blade angle solves for before you need to sharpen it. Understanding what the wood stove’s air intake controls before you’re trying to heat the house. Understanding what loop closure prevents before you’re operating under pressure.
The Teaching Sequence #
The teaching sequence must be:
- Experience the failure – Unacknowledged message creates interrupt cycle or working memory load. Feel the cost firsthand.
- Understand the cost structure – This is what breaks without acknowledgment. Not as abstract principle but as concrete experienced cost.
- Practice the protocol – Now acknowledgment has meaning. You’re not complying with authority, you’re preventing a failure mode you’ve experienced.
- Maintain under pressure – Protocol survives stress because you know what it’s protecting. When workload is high, you don’t abandon protocol – you tighten it, because that’s when failures are most expensive.
Without step 2, you get compliance without understanding. The practice survives only as long as enforcement does. This is why so many “best practices” degrade over time – they were taught as rules, not as solutions to problems people had experienced.
This teaching sequence builds what Doctrine 22 calls a “pattern library.” You’re not just learning rules – you’re accumulating experiences that let you recognize: “This is a high-cognitive-load situation, protocols need to tighten” or “This is a safe container, we can use looser protocols.” That recognition becomes intuitive with practice, enabling rapid protocol selection without conscious deliberation.
The difference between compliance and expertise is pattern recognition. The compliant actor follows rules. The expert recognizes contexts and adjusts protocols accordingly. That’s Bayesian thinking – continuously updating your assessment based on environmental cues.
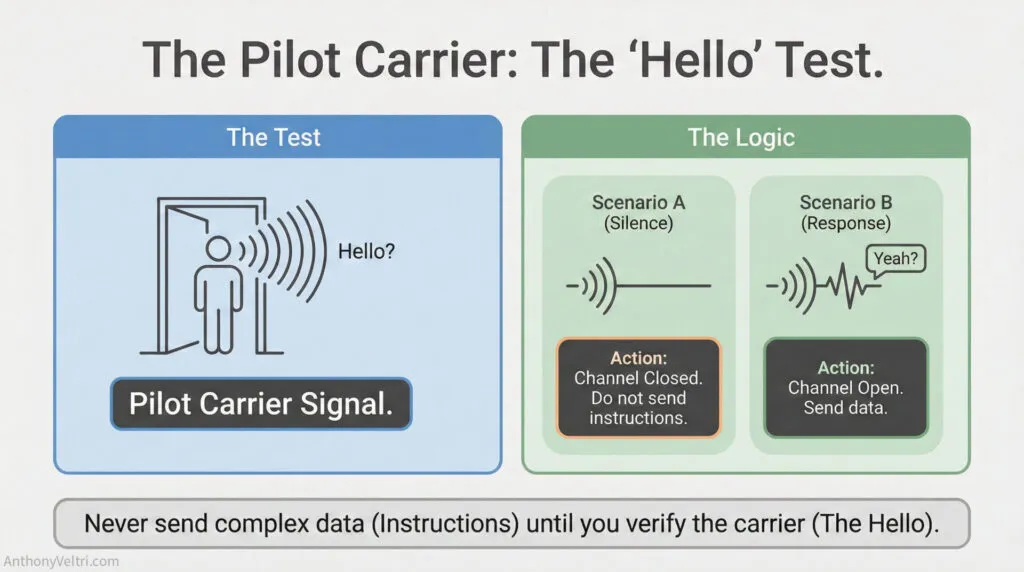
The Pilot Carrier Layer #
Before you can send substantive messages, you need confirmation that the channel is open. This is the pilot carrier – the low-level signal that proves communication infrastructure is functional before you attempt to use it.
In RF Systems #
Pilot carriers are known reference signals transmitted alongside data. They serve multiple functions: prove the channel exists, provide synchronization, enable the receiver to decode the actual data signal. Think of it as the “heartbeat” that says “transmitter is working, receiver can hear it, we’re on the same frequency.”
In more complex systems like OFDM (used in Wi-Fi, 4G/5G), pilot carriers are specific subcarriers that are always transmitted at known power levels and frequencies. The receiver uses these to figure out channel conditions – if pilot carriers are distorted, the receiver knows to compensate. If pilot carriers disappear, the receiver knows the channel has failed completely.
In Day-to-Day Life #
Same concept, different implementation. You test the channel before sending important messages.
Low-Level Pilot Carrier:
- “Hello” when entering a space
- Door opening sound combined with verbal greeting
- Saying someone’s name before instruction
- Visual presence (walking into someone’s field of view before speaking)
These signals announce “communication channel is now available” without conveying substantive information yet. You’re testing infrastructure before using it.
Example from my house:
I come in the front door. I know the acoustics of this house (1790 farmhouse, sound carries differently depending on where doors are open). When I say “hello” from the front door, I know that sound should reach the kitchen, living room, and upstairs landing if doors are open normally.
If no one responds and I know someone’s home, I now know:
- They’re in noise-isolated space (basement with door closed, upstairs bedroom with door closed)
- They’re wearing headphones
- They’re deeply focused and not attending to environment
- OR the house is empty despite cars in driveway
I’ve tested the pilot carrier. Channel is either not available or requires stronger signal. This tells me: don’t bother calling out dinner instructions from here. Either find them physically, or go to location where pilot carrier succeeds.
Without testing pilot carrier, I might waste time calling instructions to empty house or to someone who can’t hear me. The pilot carrier test is cheap (one “hello”), prevents wasted effort on substantive messages.
Body Language as Pilot Carrier #
In face-to-face contexts, body language shifts serve as pilot carriers.
You start speaking to someone. If you see no change in posture, facial expression, or orientation toward you, your pilot carrier has failed. The channel may not be open even though you’re in same physical space. They might be deeply focused on something else, cognitively unavailable despite physical presence.
This is why walking past and speaking without visual confirmation of attention is CSMA mode – you’re sending without pilot carrier confirmation. You’re assuming channel is open. If stakes are moderate or higher, you should test pilot carrier first: say name, wait for orientation toward you, then send message.
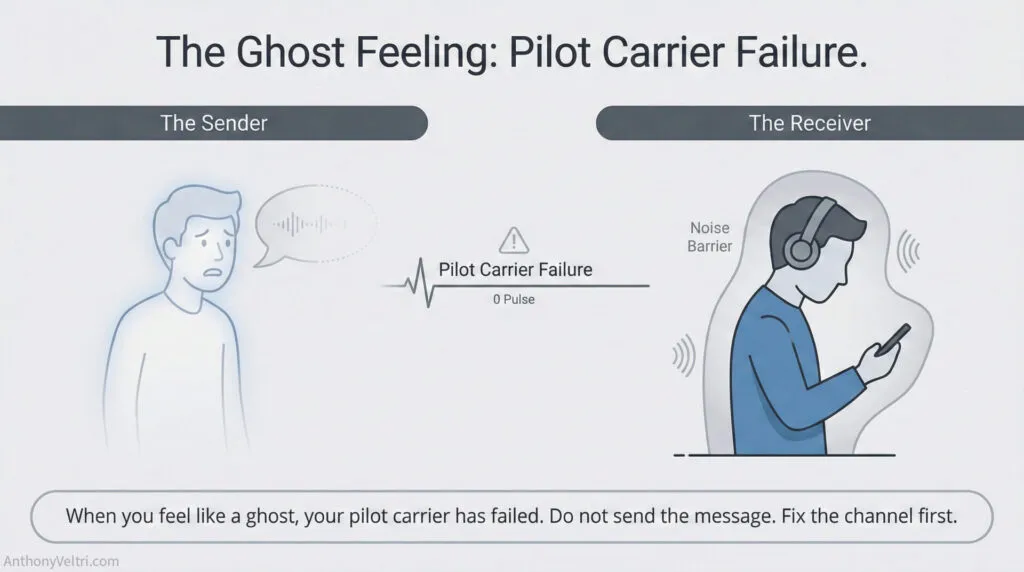
Pilot Carrier Failure Recognition #
You feel like a ghost. You’re speaking, but no response. No acknowledgment. No change in behavior. It’s as though you don’t exist.
This feeling is diagnostic: your pilot carrier is failing. The communication channel isn’t open. Don’t keep sending substantive messages – they won’t land. Fix the pilot carrier first.
In my house, when I get that ghost feeling (I’ve said something twice, no response), I stop. Don’t repeat the message again. Instead: go find the person, establish visual contact, test pilot carrier with their name, wait for acknowledgment that channel is open, then send message.
Trying to force substantive messages through a failed pilot carrier is wasteful. Fix infrastructure first.
Escalation Based on Pilot Carrier #
If pilot carrier fails repeatedly in environment where it should work, this tells you something about channel quality:
- Receiver isn’t attending to audio cues (they might need visual cues)
- Environment is noisier than you thought (need stronger signal)
- Receiver is cognitively overloaded (need to wait for better time)
- Protocol needs to escalate (shift from CSMA to CD or CA mode)
The pilot carrier isn’t just “hello.” It’s diagnostic. It tells you channel state before you commit to substantive coordination.
Wrong-Protocol Recognition Patterns #
How do you know when you’re using the wrong protocol for the situation? These are diagnostic patterns – the environmental cues that should trigger reassessment. Recognizing these patterns is a form of Recognition-Primed Decision Making: your brain notices evidence that doesn’t match your current protocol assumption and signals “time to update.”
Experienced coordinators recognize these patterns rapidly and adjust. New coordinators benefit from explicit pattern descriptions (see Doctrine 22 for the framework on building pattern recognition under uncertainty)
You’re in CSMA mode but need CD when: #
- You keep having to come back and verify (interrupt cycles accumulating)
- Tasks aren’t getting done and people claim “I didn’t know you wanted that” (messages not landing)
- You’re carrying multiple “did they hear me?” items in working memory (cognitive load building)
- Interrupt cycles are degrading your ability to complete your own tasks (CRM overload approaching)
- Same coordination failures repeating (pattern indicates systematic protocol mismatch)
This is the most common failure mode in households and teams. CSMA mode works until it doesn’t, and then you’re dealing with accumulated failures.
Fix: Shift to CD mode – add acknowledgment requirement.
You’re in CD mode but need CA when: #
- Stakes have increased significantly (consequences of message loss are now severe)
- Prior CD attempts failed (asked for acknowledgment, didn’t get it, or got ambiguous response)
- You’re at a container boundary (moving from safe to dangerous environment – home to city, office to field)
- Multiple actors must coordinate simultaneously on time-critical task
- Life safety or major consequence situation (emergency, high-risk operation)
- Environment is degraded (high noise, poor visibility, communication systems marginal)
CD mode assumes reliable acknowledgment patterns. When that assumption fails, escalate. Don’t keep trying CD mode and hoping – shift to explicit coordination.
Fix: Escalate to explicit coordination.
You’re in CA mode but should be in CD when: #
- Coordination overhead is strangling throughput (spending more time coordinating than executing)
- Low-stakes items are receiving high-stakes protocol (everything becomes “stop and acknowledge explicitly”)
- People are frustrated by over-coordination (“why do we need explicit confirmation for routine tasks?”)
- You’re spending more time establishing attention than executing tasks (coordination bottleneck)
- Team performance is degrading despite (or because of) tight protocols (protocol fatigue)
This is the over-control failure mode. CA mode is expensive. Using it for everything creates coordination bottleneck. Reserve CA for items that genuinely justify overhead.
Fix: Step down to standard acknowledgment.
System-Level Indicators: #
- If everyone is exhausted by communication overhead: Over-using CA mode, creating protocol fatigue
- If nothing is getting done because messages are lost: Under-using CD mode, need acknowledgment infrastructure
- If you’re constantly interrupting to verify: CSMA is failing, shift to CD
- If acknowledgments are unreliable despite CD mode: Environment or actors require CA escalation
The goal is protocol match: right level of coordination for stakes, pace, and environment. Too loose creates failures. Too tight creates overhead fatigue. Both degrade performance.

Addressing Common Resistance #
When you start implementing loop closure protocols, you’ll encounter resistance. Here’s how to address it:
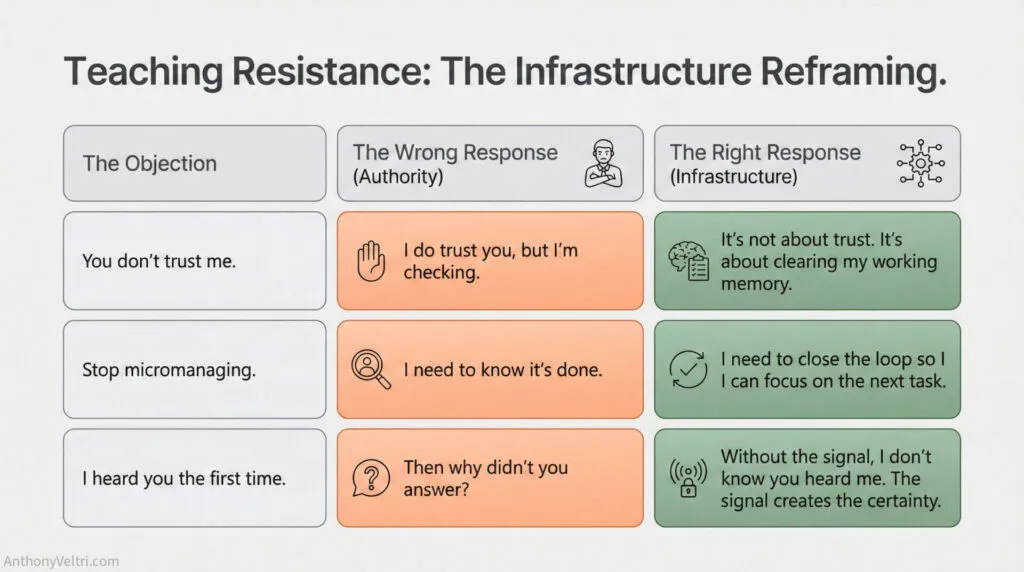
“You don’t trust me” #
Wrong frame: “I need to verify you heard me because I don’t trust you to follow through.”
Right frame: “I’m not checking because I don’t trust you. I’m checking because otherwise I don’t know if the message landed, and then I’m stuck carrying ‘did they hear me?’ while I’m trying to do three other things. The acknowledgment isn’t for you to prove anything. It’s for me to clear that item from my attention stack so I can move on to helping you with the next thing.”
Make the invisible costs visible. Most people don’t see interrupt cycles or working memory load as costs. They see verification as paranoia or micro-management. Show them the infrastructure purpose.
“This is micromanagement” #
Wrong frame: “I need constant updates because I’m checking up on you.”
Right frame: “Tight acknowledgment protocols enable loose supervision. If I can trust that when I hand something off with verified receipt, it’s actually been received and understood, I can move to the next task without checking on you. Without acknowledgment, I’m forced to hover and verify repeatedly. The protocol isn’t constraint – it’s what enables your autonomy.”
This is the federation capacity argument. Tight protocols enable loose coupling.
“This is too rigid / we’re not the military” #
Wrong frame: “Everyone must acknowledge everything explicitly at all times.”
Right frame: “Protocol matches context. Low-stakes weekend items can use CSMA mode. Moderate-stakes daily coordination uses CD mode. High-stakes or boundary transitions use CA mode. We’re not being rigid – we’re matching the coordination overhead to what the situation requires.”
Show the protocol flexibility. Use the household example where protocols shift based on context (school year start vs. mid-year vs. rushed morning vs. casual weekend).
“We’ve never needed this before” #
Wrong frame: “Our old way was broken and bad.”
Right frame: “Safe containers hide coordination costs. When everyone’s co-located and consequences are distant, loose protocols work fine. But at interfaces (remote coordination, time pressure, high stakes), those loose protocols create failures. We’re building infrastructure in the safe container so it’s there when we hit interfaces.”
This respects their current practice while showing why it won’t scale.
Integration with Existing Doctrine #
Connection to Two-Lane Systems #
Loop closure is steady-state infrastructure for the left lane (routine operations). The left lane requires reliable CD mode. Tasks are delegated with verified acknowledgment. Federation capacity is maintained.
The right lane (adaptation/response) may require CA mode when stakes spike. When you shift right because something broke or changed, protocol tightens. Explicit coordination replaces assumed acknowledgment.
Protocol shift between lanes is part of lane discipline. Team needs to recognize “we’re in right lane now, coordination protocols tighten.” That recognition must be explicit, not assumed.
Connection to Decision Altitude #
Higher decision altitude (strategic level) can often use CSMA or loose CD mode. Time scales are longer, coordination can be asynchronous, stakes are more distributed.
Lower decision altitude (tactical/operational) requires tight CD or CA mode. Time scales are compressed, coordination must be synchronous, stakes are immediate.
As stakes increase or time compresses, decision altitude drops and protocol must tighten. The acknowledgment requirements map directly to altitude: higher altitude, looser protocols; lower altitude, tighter protocols.
Connection to Federation vs. Integration #
Federated systems require tight loop closure to function. If handoffs aren’t verified, you’re forced into tighter integration (more supervision, less autonomy). The protocol tightness enables the federation capacity.
Integrated systems can sometimes use looser protocols because there’s more direct oversight. But the trade-off is reduced autonomy. The system doesn’t scale as well.
The choice between federation and integration is partly determined by whether you can maintain reliable loop closure. If you can’t trust acknowledgments, you can’t federate. You’re forced to integrate, which limits scale.
Connection to Stewardship #
Loop closure protocols are tools that solve specific problems. Understanding what they prevent (interrupt cycles, working memory overload, federation failure) before you need them under pressure is stewardship principle.
This is why the teaching sequence matters. If you only teach the action (acknowledge loudly) without the cost structure (this prevents these specific failures), you haven’t transferred stewardship. You’ve transferred compliance.
Stewardship means understanding why the scythe blade is angled that way before you need to maintain it. Understanding why loop closure matters before you’re operating under pressure where protocol discipline determines outcomes.
Practical Implementation #
For Individuals #
- Notice when you’re carrying “did they hear me?” in working memory. This is diagnostic. If you’re tracking unverified messages while trying to do other things, you’re burning cognitive capacity. That’s the cost you need to make visible to yourself and others.
- Count interrupt cycles per day. How many times do you stop what you’re doing to verify whether someone heard you? Each cycle is expensive. If you’re executing 5+ per day, your coordination protocols are failing.
- Practice asking for acknowledgment explicitly: “I need to hear you say ‘got it’ so I know you heard me.” Frame it as your need (to clear working memory), not their obligation (to prove they’re listening). That framing works better.
- Explain the cost structure: “I’m not checking because I don’t trust you. I’m checking because otherwise I don’t know if the message landed, and then I have to either stop and come back (interrupt cycle), or keep worrying about whether you heard me (working memory load). The acknowledgment frees me to move on.”
Make the invisible costs visible. Most people don’t see interrupt cycles or working memory load as costs. They see verification as paranoia or micro-management. Show them the infrastructure purpose.
For Teams #
- Establish standard acknowledgment protocol for moderate-stakes items. CD mode as baseline. “When delegating tasks, we acknowledge by repeating the key action: ‘Got it, I’ll have the report by Friday.'” Make the protocol explicit and default.
- Practice CD mode in low-stakes environments. Team meetings, routine handoffs, daily standups. Build the habit when stakes are low so protocol is available when stakes increase. Don’t wait for emergency to establish loop closure.
- Explicitly shift to CA mode when stakes spike: “This is CA mode – I need explicit confirmation before we proceed.” Name the protocol shift. Don’t assume everyone recognizes when coordination needs to tighten. Make the escalation visible.
- Debrief protocol failures: “What we just experienced was CSMA failure creating interrupt cycles. Notice how much time we spent re-verifying whether instructions landed? That’s the cost of loose protocols in high-stakes context.” Use failures as teaching moments for cost structure.
- Create visual protocol indicators. In war rooms or command centers, you might literally have a sign showing current protocol level: “CD Mode – Standard Ops” or “CA Mode – All Confirmations Explicit.” This makes the current protocol state visible to everyone.
For Families #
- Teach the cost structure: “When I don’t hear ‘got it,’ I have to either stop and come back (show the interrupt), or keep worrying about whether you heard me (show the working memory cost). You’re not doing it so I know you’re obedient. You’re doing it so I know the message landed and I can clear it from my mind and help you with the next thing.”
My kids started responding better when I explained it this way. It’s not about authority. It’s about infrastructure. They can understand “Dad needs to know the message arrived so he can move on to helping you with the next thing.”
- Practice in safe container (home) before testing at interfaces. Build CD mode habits during low-stakes weekend routines. That way when you’re in busy city or travel day with tight connections, the protocol is already there. You can invoke it without teaching in the moment.
- Recognize when kids are tightening protocols on their own. When my kids start giving clear acknowledgments without prompting, especially at interfaces (busy parking lot, crowded event), that’s evidence they’ve internalized the principle. They’re not complying – they’re operating infrastructure they understand.
- Model good acknowledgment. When they tell you something, acknowledge clearly. “Got it, I’ll pick you up at 3.” Show them what good loop closure looks like. They learn as much from watching you close loops as from being told to do it.
- Use protocol flexibility as teaching tool. Explicitly discuss when protocols shift: “We’re entering the city now, so we’re shifting to tighter acknowledgment. When I tell you something, I need to hear ‘got it’ immediately.” Then later: “We’re home now, back to relaxed mode for low-stakes stuff.” This teaches them to read context and adjust protocols, not just follow rules.
Teaching Resistance #
Some people will resist acknowledgment requirements. Common objections and how to address them:
“You don’t trust me”
Response: “I trust you completely. This isn’t about trust. It’s about infrastructure. Without acknowledgment, I don’t know if message landed. So I’m either stuck checking repeatedly (interrupt cycle), or carrying ‘did they hear me?’ while doing other things (working memory load). The acknowledgment isn’t for you to prove anything. It’s for me to clear that item from my attention stack so I can move on to helping you with the next thing.”
“This is micromanagement”
Response: “Actually, it’s the opposite. Tight acknowledgment protocols enable loose supervision. If I can trust that when I hand something off, it’s been verified received, I can leave you alone and trust it’ll get done. Without acknowledgment, I’m forced to hover and verify repeatedly. The protocol isn’t constraint – it’s what enables your independence.”
“This is too rigid”
Response: “We’re not using the same protocol for everything. Low-stakes items use loose confirmation. Daily coordination uses standard acknowledgment. High-stakes or time-critical situations use explicit confirmation. We match the overhead to what the situation requires. That’s not rigid – that’s appropriate.”
“We’ve never needed this before”
Response: “Safe containers hide coordination costs. When everyone’s nearby and stakes are low, loose protocols work. But at interfaces – remote work, time pressure, high stakes – those loose protocols create failures. We’re building infrastructure now so it’s there when we need it.”
Most people respond to infrastructure framing better than authority framing. They can see coordination costs once you name them. They thought you were checking on their compliance. You’re actually trying to clear your working memory so you can help them with the next thing.
Conclusion #
Loop closure is not courtesy. It is load-bearing infrastructure that determines whether distributed actors can coordinate under pressure.
The “Roger, Runway 34 Left, Cessna 19 Echo” isn’t radio tradition or military formality. It’s what enables multiple aircraft to share airspace without constant supervision. The tower controller clears an aircraft, gets confirmation, clears working memory, coordinates next aircraft. That’s federation capacity at scale.
The “got it” from your child isn’t obedience signaling or respect display. It’s what lets you clear that task from your cognitive load and move to the next thing. It’s what enables you to delegate effectively without hovering. That’s federation capacity in the household.
Unverified message receipt creates three costs across three dimensions:
Direct costs: Interrupt cycles now, working memory load during. These are visible to the sender but often invisible to receiver.
Container/interface costs: Protocol sloppiness in safe containers creates failures at interfaces. You can’t learn tight coordination when you need it – you must practice when you don’t need it.
Federation costs: Loose protocols force tight coupling. Without verified handoffs, you cannot operate independently. The system doesn’t scale.
The third cost is least visible and most consequential. Systems that cannot trust handoffs cannot scale. Federation capacity depends on loop closure infrastructure.
The protocol you choose – CSMA, CD, or CA – should match stakes, pace, and environment. Wrong selection creates either message loss (under-coordination) or coordination bottleneck (over-coordination). Recognition patterns exist for both failure modes. When you notice interrupt cycles accumulating, shift from CSMA to CD. When stakes spike, shift from CD to CA. When overhead is strangling throughput, step down from CA to CD.
Most importantly: the practice only survives pressure if you understand what it prevents.
Teaching “acknowledge loudly” without teaching “this is what breaks without acknowledgment” creates ritual compliance, not operational capacity. The acknowledgment becomes performance, not infrastructure. It survives only as long as enforcement does.
The minimum separation between doing and understanding is this: you must grasp the cost structure before the protocol becomes meaningful in your hands.
Experience the failure. Understand what breaks. Practice the protocol. Maintain under pressure. That sequence builds infrastructure, not compliance.
This is stewardship. Understanding why the tool was designed that way before you need it under pressure. Understanding what the scythe’s blade angle solves for before you sharpen it. Understanding what loop closure prevents before you’re coordinating under load where protocol discipline determines whether people stay safe and whether missions succeed.
The young hooah shouting acknowledgments without understanding why sounds loud but lacks purpose. They learned volume, not infrastructure. They’ll maintain protocol under supervision but abandon it under stress because they don’t know what breaks without it.
The professional who understands loop closure as load-bearing infrastructure maintains protocol especially under stress. That’s when it matters most. That’s when coordination failures are most expensive. That’s when working memory is most precious and federation capacity is most critical.
Build the infrastructure in safe containers. Understand the cost structure. Practice the protocols. They’ll be there when you need them.
Last Updated on December 12, 2025